

Kryo is a fast and efficient binary object graph serialization framework for Java. The goals of the project are high speed, low size, and an easy to use API. The project is useful any time objects need to be persisted, whether to a file, database, or over the network.
Kryo can also perform automatic deep and shallow copying/cloning. This is direct copying from object to object, not object to bytes to object.
Contact / Mailing list
Please use the Kryo mailing list for questions, discussions, and support. Please limit use of the Kryo issue tracker to bugs and enhancements, not questions, discussions, or support.
Table of contents
- Recent releases
- Installation
- Quickstart
- IO
- Reading and writing objects
- Serializer framework
- Implementing a serializer
- Kryo versioning and upgrading
- Interoperability
- Compatibility
- Serializers
- Logging
- Thread safety
- Benchmarks
- Links
Recent releases
- 5.0.1 - brings several incremental fixes and improvements.
- 5.0.0 - the final Kryo 5 release fixing many issues and making many long awaited improvements over Kryo 4. Note: For libraries (not applications) using Kryo, there's now a completely self-contained, versioned artifact (for details see installation). For migration from Kryo 4.x see also Migration to v5.
- 4.0.2 - brings several incremental fixes and improvements.
Installation
Kryo publishes two kinds of artifacts/jars:
- the default jar (with the usual library dependencies) which is meant for direct usage in applications (not libraries)
- a dependency-free, "versioned" jar which should be used by other libraries. Different libraries shall be able to use different major versions of Kryo.
Kryo JARs are available on the releases page and at Maven Central. The latest snapshots of Kryo, including snapshot builds of master, are in the Sonatype Repository.
With Maven
To use the latest Kryo release in your application, use this dependency entry in your pom.xml:
<dependency>
<groupId>com.esotericsoftware</groupId>
<artifactId>kryo</artifactId>
<version>5.0.1</version>
</dependency>
To use the latest Kryo release in a library you want to publish, use this dependency entry in your pom.xml:
<dependency>
<groupId>com.esotericsoftware.kryo</groupId>
<artifactId>kryo5</artifactId>
<version>5.0.1</version>
</dependency>
To use the latest Kryo snapshot, use:
<repository>
<id>sonatype-snapshots</id>
<name>sonatype snapshots repo</name>
<url>https://oss.sonatype.org/content/repositories/snapshots</url>
</repository>
<!-- for usage in an application: -->
<dependency>
<groupId>com.esotericsoftware</groupId>
<artifactId>kryo</artifactId>
<version>5.0.2-SNAPSHOT</version>
</dependency>
<!-- for usage in a library that should be published: -->
<dependency>
<groupId>com.esotericsoftware.kryo</groupId>
<artifactId>kryo5</artifactId>
<version>5.0.2-SNAPSHOT</version>
</dependency>
Without Maven
Not everyone is a Maven fan. Using Kryo without Maven requires placing the Kryo JAR on your classpath along with the dependency JARs found in lib.
Quickstart
Jumping ahead to show how the library can be used:
import com.esotericsoftware.kryo.Kryo;
import com.esotericsoftware.kryo.io.Input;
import com.esotericsoftware.kryo.io.Output;
import java.io.*;
public class HelloKryo {
static public void main (String[] args) throws Exception {
Kryo kryo = new Kryo();
kryo.register(SomeClass.class);
SomeClass object = new SomeClass();
object.value = "Hello Kryo!";
Output output = new Output(new FileOutputStream("file.bin"));
kryo.writeObject(output, object);
output.close();
Input input = new Input(new FileInputStream("file.bin"));
SomeClass object2 = kryo.readObject(input, SomeClass.class);
input.close();
}
static public class SomeClass {
String value;
}
}
The Kryo class performs the serialization automatically. The Output and Input classes handle buffering bytes and optionally flushing to a stream.
The rest of this document details how this works and advanced usage of the library.
IO
Getting data in and out of Kryo is done using the Input and Output classes. These classes are not thread safe.
Output
The Output class is an OutputStream that writes data to a byte array buffer. This buffer can be obtained and used directly, if a byte array is desired. If the Output is given an OutputStream, it will flush the bytes to the stream when the buffer becomes full, otherwise Output can grow its buffer automatically. Output has many methods for efficiently writing primitives and strings to bytes. It provides functionality similar to DataOutputStream, BufferedOutputStream, FilterOutputStream, and ByteArrayOutputStream, all in one class.
Tip: Output and Input provide all the functionality of ByteArrayOutputStream. There is seldom a reason to have Output flush to a ByteArrayOutputStream.
Output buffers the bytes when writing to an OutputStream, so flush or close must be called after writing is complete to cause the buffered bytes to be written to the OutputStream. If the Output has not been provided an OutputStream, calling flush or close is unnecessary. Unlike many streams, an Output instance can be reused by setting the position, or setting a new byte array or stream.
Tip: Since Output buffers already, there is no reason to have Output flush to a BufferedOutputStream.
The zero argument Output constructor creates an uninitialized Output. Output setBuffer must be called before the Output can be used.
Input
The Input class is an InputStream that reads data from a byte array buffer. This buffer can be set directly, if reading from a byte array is desired. If the Input is given an InputStream, it will fill the buffer from the stream when all the data in the buffer has been read. Input has many methods for efficiently reading primitives and strings from bytes. It provides functionality similar to DataInputStream, BufferedInputStream, FilterInputStream, and ByteArrayInputStream, all in one class.
Tip: Input provides all the functionality of ByteArrayInputStream. There is seldom a reason to have Input read from a ByteArrayInputStream.
If the Input close is called, the Input's InputStream is closed, if any. If not reading from an InputStream then it is not necessary to call close. Unlike many streams, an Input instance can be reused by setting the position and limit, or setting a new byte array or InputStream.
The zero argument Input constructor creates an uninitialized Input. Input setBuffer must be called before the Input can be used.
ByteBuffers
The ByteBufferOutput and ByteBufferInput classes work exactly like Output and Input, except they use a ByteBuffer rather than a byte array.
Unsafe buffers
The UnsafeOutput, UnsafeInput, UnsafeByteBufferOutput, and UnsafeByteBufferInput classes work exactly like their non-unsafe counterparts, except they use sun.misc.Unsafe for higher performance in many cases. To use these classes Util.unsafe must be true.
The downside to using unsafe buffers is that the native endianness and representation of numeric types of the system performing the serialization affects the serialized data. For example, deserialization will fail if the data is written on X86 and read on SPARC. Also, if data is written with an unsafe buffer, it must be read with an unsafe buffer.
The biggest performance difference with unsafe buffers is with large primitive arrays when variable length encoding is not used. Variable length encoding can be disabled for the unsafe buffers or only for specific fields (when using FieldSerializer).
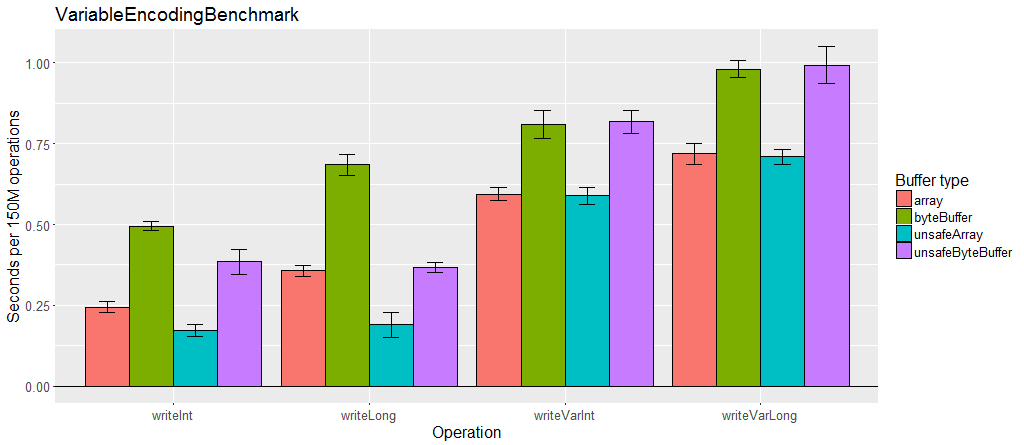
Variable length encoding
The IO classes provide methods to read and write variable length int (varint) and long (varlong) values. This is done by using the 8th bit of each byte to indicate if more bytes follow, which means a varint uses 1-5 bytes and a varlong uses 1-9 bytes. Using variable length encoding is more expensive but makes the serialized data much smaller.
When writing a variable length value, the value can be optimized either for positive values or for both negative and positive values. For example, when optimized for positive values, 0 to 127 is written in one byte, 128 to 16383 in two bytes, etc. However, small negative numbers are the worst case at 5 bytes. When not optimized for positive, these ranges are shifted down by half. For example, -64 to 63 is written in one byte, 64 to 8191 and -65 to -8192 in two bytes, etc.
Input and Output buffers provides methods to read and write fixed sized or variable length values. There are also methods to allow the buffer to decide whether a fixed size or variable length value is written. This allows serialization code to ensure variable length encoding is used for very common values that would bloat the output if a fixed size were used, while still allowing the buffer configuration to decide for all other values.
| Method | Description |
|---|---|
| writeInt(int) | Writes a 4 byte int. |
| writeVarInt(int, boolean) | Writes a 1-5 byte int. |
| writeInt(int, boolean) | Writes either a 4 or 1-5 byte int (the buffer decides). |
| writeLong(long) | Writes an 8 byte long. |
| writeVarLong(long, boolean) | Writes an 1-9 byte long. |
| writeLong(long, boolean) | Writes either an 8 or 1-9 byte long (the buffer decides). |
To disable variable length encoding for all values, the writeVarInt, writeVarLong, readVarInt, and readVarLong methods would need to be overridden.
Chunked encoding
It can be useful to write the length of some data, then the data. When the length of the data is not known ahead of time, all the data needs to be buffered to determine its length, then the length can be written, then the data. using a single, large buffer for this would prevent streaming and may require an unreasonably large buffer, which is not ideal.
Chunked encoding solves this problem by using a small buffer. When the buffer is full, its length is written, then the data. This is one chunk of data. The buffer is cleared and this continues until there is no more data to write. A chunk with a length of zero denotes the end of the chunks.
Kryo provides classes to maked chunked encoding. OutputChunked is used to write chunked data. It extends Output, so has all the convenient methods to write data. When the OutputChunked buffer is full, it flushes the chunk to another OutputStream. The endChunk method is used to mark the end of a set of chunks.
OutputStream outputStream = new FileOutputStream("file.bin");
OutputChunked output = new OutputChunked(outputStream, 1024);
// Write data to output...
output.endChunk();
// Write more data to output...
output.endChunk();
// Write even more data to output...
output.endChunk();
output.close();
To read the chunked data, InputChunked is used. It extends Input, so has all the convenient methods to read data. When reading, InputChunked will appear to hit the end of the data when it reaches the end of a set of chunks. The nextChunks method advances to the next set of chunks, even if not all the data has been read from the current set of chunks.
InputStream outputStream = new FileInputStream("file.bin");
InputChunked input = new InputChunked(inputStream, 1024);
// Read data from first set of chunks...
input.nextChunks();
// Read data from second set of chunks...
input.nextChunks();
// Read data from third set of chunks...
input.close();
Buffer performance
Generally Output and Input provide good performance. Unsafe buffers perform as well or better, especially for primitive arrays, if their crossplatform incompatibilities are acceptable. ByteBufferOutput and ByteBufferInput provide slightly worse performance, but this may be acceptable if the final destination of the bytes must be a ByteBuffer.
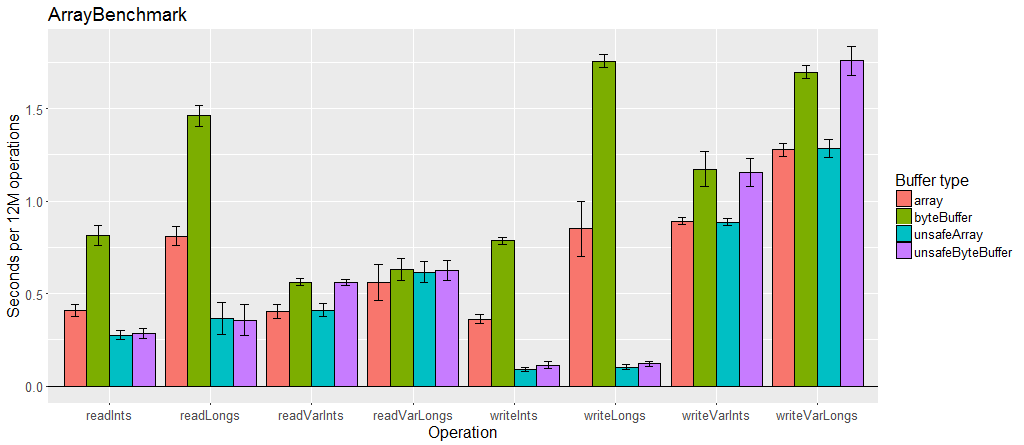
Variable length encoding is slower than fixed values, especially when there is a lot of data using it.
Chunked encoding uses an intermediary buffer so it adds one additional copy of all the bytes. This alone may be acceptable, however when used in a reentrant serializer, the serializer must create an OutputChunked or InputChunked for each object. Allocating and garbage collecting those buffers during serialization can have a negative impact on performance.
Reading and writing objects
Kryo has three sets of methods for reading and writing objects. If the concrete class of the object is not known and the object could be null:
kryo.writeClassAndObject(output, object);
Object object = kryo.readClassAndObject(input);
if (object instanceof SomeClass) {
// ...
}
If the class is known and the object could be null:
kryo.writeObjectOrNull(output, object);
SomeClass object = kryo.readObjectOrNull(input, SomeClass.class);
If the class is known and the object cannot be null:
kryo.writeObject(output, object);
SomeClass object = kryo.readObject(input, SomeClass.class);
All of these methods first find the appropriate serializer to use, then use that to serialize or deserialize the object. Serializers can call these methods for recursive serialization. Multiple references to the same object and circular references are handled by Kryo automatically.
Besides methods to read and write objects, the Kryo class provides a way to register serializers, reads and writes class identifiers efficiently, handles null objects for serializers that can't accept nulls, and handles reading and writing object references (if enabled). This allows serializers to focus on their serialization tasks.
Round trip
While testing and exploring Kryo APIs, it can be useful to write an object to bytes, then read those bytes back to an object.
Kryo kryo = new Kryo();
// Register all classes to be serialized.
kryo.register(SomeClass.class);
SomeClass object1 = new SomeClass();
Output output = new Output(1024, -1);
kryo.writeObject(output, object1);
Input input = new Input(output.getBuffer(), 0, output.position());
SomeClass object2 = kryo.readObject(input, SomeClass.class);
In this example the Output starts with a buffer that has a capacity of 1024 bytes. If more bytes are written to the Output, the buffer will grow in size without limit. The Output does not need to be closed because it has not been given an OutputStream. The Input reads directly from the Output's byte[] buffer.
Deep and shallow copies
Kryo supports making deep and shallow copies of objects using direct assignment from one object to another. This is more efficient than serializing to bytes and back to objects.
Kryo kryo = new Kryo();
SomeClass object = ...
SomeClass copy1 = kryo.copy(object);
SomeClass copy2 = kryo.copyShallow(object);
All the serializers being used need to support copying. All serializers provided with Kryo support copying.
Like with serialization, when copying, multiple references to the same object and circular references are handled by Kryo automatically if references are enabled.
If using Kryo only for copying, registration can be safely disabled.
Kryo getOriginalToCopyMap can be used after an object graph is copied to obtain a map of old to new objects. The map is cleared automatically by Kryo reset, so is only useful when Kryo setAutoReset is false.
References
By default references are not enabled. This means if an object appears in an object graph multiple times, it will be written multiple times and will be deserialized as multiple, different objects. When references are disabled, circular references will cause serialization to fail. References are enabled or disabled with Kryo setReferences for serialization and setCopyReferences for copying.
When references are enabled, a varint is written before each object the first time it appears in the object graph. For subsequent appearances of that class within the same object graph, only a varint is written. After deserialization the object references are restored, including any circular references. The serializers in use must support references by calling Kryo reference in Serializer read.
Enabling references impacts performance because every object that is read or written needs to be tracked.
ReferenceResolver
Under the covers, a ReferenceResolver handles tracking objects that have been read or written and provides int reference IDs. Multiple implementations are provided:
- MapReferenceResolver is used by default if a reference resolver is not specified. It uses Kryo's IdentityObjectIntMap (a cuckoo hashmap) to track written objects. This kind of map has very fast gets and does not allocate for put, but puts for very large numbers of objects can be somewhat slow.
- HashMapReferenceResolver uses a HashMap to track written objects. This kind of map allocates for put but may provide better performance for object graphs with a very high number of objects.
- ListReferenceResolver uses an ArrayList to track written objects. For object graphs with relatively few objects, this can be faster than using a map (~15% faster in some tests). This should not be used for graphs with many objects because it has a linear look up to find objects that have already been written.
ReferenceResolver useReferences(Class) can be overridden. It returns a boolean to decide if references are supported for a class. If a class doesn't support references, the varint reference ID is not written before objects of that type. If a class does not need references and objects of that type appear in the object graph many times, the serialized size can be greatly reduced by disabling references for that class. The default reference resolver returns false for all primitive wrappers and enums. It is common to also return false for String and other classes, depending on the object graphs being serialized.
public boolean useReferences (Class type) {
return !Util.isWrapperClass(type) && !Util.isEnum(type) && type != String.class;
}
Reference limits
The reference resolver determines the maximum number of references in a single object graph. Java array indices are limited to Integer.MAX_VALUE, so reference resolvers that use data structures based on arrays may result in a java.lang.NegativeArraySizeException when serializing more than ~2 billion objects. Kryo uses int class IDs, so the maximum number of references in a single object graph is limited to the full range of positive and negative numbers in an int (~4 billion).
Context
Kryo getContext returns a map for storing user data. The Kryo instance is available to all serializers, so this data is easily accessible to all serializers.
Kryo getGraphContext is similar, but is cleared after each object graph is serialized or deserialized. This makes it easy to manage state that is only relevant for the current object graph. For example, this can be used to write some schema data the first time a class is encountered in an object graph. See CompatibleFieldSerializer for an example.
Reset
By default, Kryo reset is called after each entire object graph is serialized. This resets unregistered class names in the class resolver, references to previously serialized or deserialized objects in the reference resolver, and clears the graph context. Kryo setAutoReset(false) can be used to disable calling reset automatically, allowing that state to span multiple object graphs.
Serializer framework
Kryo is a framework to facilitate serialization. The framework itself doesn't enforce a schema or care what or how data is written or read. Serializers are pluggable and make the decisions about what to read and write. Many serializers are provided out of the box to read and write data in various ways. While the provided serializers can read and write most objects, they can easily be replaced partially or completely with your own serializers.
Registration
When Kryo goes to write an instance of an object, first it may need to write something that identifies the object's class. By default, all classes that Kryo will read or write must be registered beforehand. Registration provides an int class ID, the serializer to use for the class, and the object instantiator used to create instances of the class.
Kryo kryo = new Kryo();
kryo.register(SomeClass.class);
Output output = ...
SomeClass object = ...
kryo.writeObject(output, object);
During deserialization, the registered classes must have the exact same IDs they had during serialization. When registered, a class is assigned the next available, lowest integer ID, which means the order classes are registered is important. The class ID can optionally be specified explicitly to make order unimportant:
Kryo kryo = new Kryo();
kryo.register(SomeClass.class, 9);
kryo.register(AnotherClass.class, 10);
kryo.register(YetAnotherClass.class, 11);
Class IDs -1 and -2 are reserved. Class IDs 0-8 are used by default for primitive types and String, though these IDs can be repurposed. The IDs are written as positive optimized varints, so are most efficient when they are small, positive integers. Negative IDs are not serialized efficiently.
ClassResolver
Under the covers, a ClassResolver handles actually reading and writing bytes to represent a class. The default implementation is sufficient in most cases, but it can be replaced to customize what happens when a class is registered, what an unregistered class is encountered during serialization, and what is read and written to represent a class.
Optional registration
Kryo can be configured to allow serialization without registering classes up front.
Kryo kryo = new Kryo();
kryo.setRegistrationRequired(false);
Output output = ...
SomeClass object = ...
kryo.writeObject(output, object);
Use of registered and unregistered classes can be mixed. Unregistered classes have two major drawbacks:
- There are security implications because it allows deserialization to create instances of any class. Classes with side effects during construction or finalization could be used for malicious purposes.
- Instead of writing a varint class ID (often 1-2 bytes), the fully qualified class name is written the first time an unregistered class appears in the object graph. Subsequent appearances of that class within the same object graph are written using a varint. Short package names could be considered to reduce the serialized size.
If using Kryo only for copying, registration can be safely disabled.
When registration is not required, Kryo setWarnUnregisteredClasses can be enabled to log a message when an unregistered class is encountered. This can be used to easily obtain a list of all unregistered classes. Kryo unregisteredClassMessage can be overridden to customize the log message or take other actions.
Default serializers
When a class is registered, a serializer instance can optionally be specified. During deserialization, the registered classes must have the exact same serializers and serializer configurations they had during serialization.
Kryo kryo = new Kryo();
kryo.register(SomeClass.class, new SomeSerializer());
kryo.register(AnotherClass.class, new AnotherSerializer());
If a serializer is not specified or when an unregistered class is encountered, a serializer is chosen automatically from a list of "default serializers" that maps a class to a serializer. Having many default serializers doesn't affect serialization performance, so by default Kryo has 50+ default serializers for various JRE classes. Additional default serializers can be added:
Kryo kryo = new Kryo();
kryo.setRegistrationRequired(false);
kryo.addDefaultSerializer(SomeClass.class, SomeSerializer.class);
Output output = ...
SomeClass object = ...
kryo.writeObject(output, object);
This will cause a SomeSerializer instance to be created when SomeClass or any class which extends or implements SomeClass is registered.
Default serializers are sorted so more specific classes are matched first, but are otherwise matched in the order they are added. The order they are added can be relevant for interfaces.
If no default serializers match a class, then the global default serializer is used. The global default serializer is set to FieldSerializer by default, but can be changed. Usually the global serializer is one that can handle many different types.
Kryo kryo = new Kryo();
kryo.setDefaultSerializer(TaggedFieldSerializer.class);
kryo.register(SomeClass.class);
With this code, assuming no default serializers match SomeClass, TaggedFieldSerializer will be used.
A class can also use the DefaultSerializer annotation, which will be used instead of choosing one of Kryo's default serializers:
@DefaultSerializer(SomeClassSerializer.class)
public class SomeClass {
// ...
}
For maximum flexibility, Kryo getDefaultSerializer can be overridden to implement custom logic for choosing and instantiating a serializer.
Serializer factories
The addDefaultSerializer(Class, Class) method does not allow for configuration of the serializer. A serializer factory can be set instead of a serializer class, allowing the factory to create and configure each serializer instance. Factories are provided for common serializers, often with a getConfig method to configure the serializers that are created.
Kryo kryo = new Kryo();
TaggedFieldSerializerFactory defaultFactory = new TaggedFieldSerializerFactory();
defaultFactory.getConfig().setReadUnknownTagData(true);
kryo.setDefaultSerializer(defaultFactory);
FieldSerializerFactory someClassFactory = new FieldSerializerFactory();
someClassFactory.getConfig().setFieldsCanBeNull(false);
kryo.register(SomeClass.class, someClassFactory);
The serializer factory has an isSupported(Class) method which allows it to decline to handle a class, even if it otherwise matches the class. This allows a factory to check for multiple interfaces or implement other logic.
Object creation
While some serializers are for a specific class, others can serialize many different classes. Serializers can use Kryo newInstance(Class) to create an instance of any class. This is done by looking up the registration for the class, then using the registration's ObjectInstantiator. The instantiator can be specified on the registration.
Registration registration = kryo.register(SomeClass.class);
registration.setInstantiator(new ObjectInstantiator<SomeClass>() {
public SomeClass newInstance () {
return new SomeClass("some constructor arguments", 1234);
}
});
If the registration doesn't have an instantiator, one is provided by Kryo newInstantiator. To customize how objects are created, Kryo newInstantiator can be overridden or an InstantiatorStrategy provided.
InstantiatorStrategy
Kryo provides DefaultInstantiatorStrategy which creates objects using ReflectASM to call a zero argument constructor. If that is not possible, it uses reflection to call a zero argument constructor. If that also fails, then it either throws an exception or tries a fallback InstantiatorStrategy. Reflection uses setAccessible, so a private zero argument constructor can be a good way to allow Kryo to create instances of a class without affecting the public API.
DefaultInstantiatorStrategy is the recommended way of creating objects with Kryo. It runs constructors just like would be done with Java code. Alternative, extralinguistic mechanisms can also be used to create objects. The Objenesis StdInstantiatorStrategy uses JVM specific APIs to create an instance of a class without calling any constructor at all. Using this is dangerous because most classes expect their constructors to be called. Creating the object by bypassing its constructors may leave the object in an uninitialized or invalid state. Classes must be designed to be created in this way.
Kryo can be configured to try DefaultInstantiatorStrategy first, then fallback to StdInstantiatorStrategy if necessary.
kryo.setInstantiatorStrategy(new DefaultInstantiatorStrategy(new StdInstantiatorStrategy()));
Another option is SerializingInstantiatorStrategy, which uses Java's built-in serialization mechanism to create an instance. Using this, the class must implement java.io.Serializable and the first zero argument constructor in a super class is invoked. This also bypasses constructors and so is dangerous for the same reasons as StdInstantiatorStrategy.
kryo.setInstantiatorStrategy(new DefaultInstantiatorStrategy(new SerializingInstantiatorStrategy()));
Overriding create
Alternatively, some generic serializers provide methods that can be overridden to customize object creation for a specific type, instead of calling Kryo newInstance.
kryo.register(SomeClass.class, new FieldSerializer(kryo, SomeClass.class) {
protected T create (Kryo kryo, Input input, Class<? extends T> type) {
return new SomeClass("some constructor arguments", 1234);
}
});
Some serializers provide a writeHeader method that can be overridden to write data that is needed in create at the right time.
static public class TreeMapSerializer extends MapSerializer<TreeMap> {
protected void writeHeader (Kryo kryo, Output output, TreeMap map) {
kryo.writeClassAndObject(output, map.comparator());
}
protected TreeMap create (Kryo kryo, Input input, Class<? extends TreeMap> type, int size) {
return new TreeMap((Comparator)kryo.readClassAndObject(input));
}
}
If a serializer doesn't provide writeHeader, writing data for create can be done in write.
static public class SomeClassSerializer extends FieldSerializer<SomeClass> {
public SomeClassSerializer (Kryo kryo) {
super(kryo, SomeClass.class);
}
public void write (Kryo kryo, Output output, SomeClass object) {
output.writeInt(object.value);
}
protected SomeClass create (Kryo kryo, Input input, Class<? extends SomeClass> type) {
return new SomeClass(input.readInt());
}
}
Final classes
Even when a serializer knows the expected class for a value (eg a field's class), if the value's concrete class is not final then the serializer needs to first write the class ID, then the value. Final classes can be serialized more efficiently because they are non-polymorphic.
Kryo isFinal is used to determine if a class is final. This method can be overridden to return true even for types which are not final. For example, if an application uses ArrayList extensively but never uses an ArrayList subclass, treating ArrayList as final could allow FieldSerializer to save 1-2 bytes per ArrayList field.
Closures
Kryo can serialize Java 8+ closures that implement java.io.Serializable, with some caveats. Closures serialized on one JVM may fail to be deserialized on a different JVM.
Kryo isClosure is used to determine if a class is a closure. If so, then ClosureSerializer.Closure is used to find the class registration instead of the closure's class. To serialize closures, the following classes must be registered: ClosureSerializer.Closure, SerializedLambda, Object[], and Class. Additionally, the closure's capturing class must be registered.
kryo.register(Object[].class);
kryo.register(Class.class);
kryo.register(SerializedLambda.class);
kryo.register(ClosureSerializer.Closure.class, new ClosureSerializer());
kryo.register(CapturingClass.class);
Callable<Integer> closure1 = (Callable<Integer> & java.io.Serializable)( () -> 72363 );
Output output = new Output(1024, -1);
kryo.writeObject(output, closure1);
Input input = new Input(output.getBuffer(), 0, output.position());
Callable<Integer> closure2 = (Callable<Integer>)kryo.readObject(input, ClosureSerializer.Closure.class);
Serializing closures which do not implement Serializable is possible with some effort.
Compression and encryption
Kryo supports streams, so it is trivial to use compression or encryption on all of the serialized bytes:
OutputStream outputStream = new DeflaterOutputStream(new FileOutputStream("file.bin"));
Output output = new Output(outputStream);
Kryo kryo = new Kryo();
kryo.writeObject(output, object);
output.close();
If needed, a serializer can be used to compress or encrypt the bytes for only a subset of the bytes for an object graph. For example, see DeflateSerializer or BlowfishSerializer. These serializers wrap another serializer to encode and decode the bytes.
Implementing a serializer
The Serializer abstract class defines methods to go from objects to bytes and bytes to objects.
public class ColorSerializer extends Serializer<Color> {
public void write (Kryo kryo, Output output, Color color) {
output.writeInt(color.getRGB());
}
public Color read (Kryo kryo, Input input, Class<? extends Color> type) {
return new Color(input.readInt());
}
}
Serializer has only two methods that must be implemented. write writes the object as bytes to the Output. read creates a new instance of the object and reads from the Input to populate it.
Serializer references
When Kryo is used to read a nested object in Serializer read then Kryo reference must first be called with the parent object if it is possible for the nested object to reference the parent object. It is unnecessary to call Kryo reference if the nested objects can't possibly reference the parent object, if Kryo is not being used for nested objects, or if references are not being used. If nested objects can use the same serializer, the serializer must be reentrant.
public SomeClass read (Kryo kryo, Input input, Class<? extends SomeClass> type) {
SomeClass object = new SomeClass();
kryo.reference(object);
// Read objects that may reference the SomeClass instance.
object.someField = kryo.readClassAndObject(input);
return object;
}
Nested serializers
Serializers should not usually make direct use of other serializers, instead the Kryo read and write methods should be used. This allows Kryo to orchestrate serialization and handle features such as references and null objects. Sometimes a serializer knows which serializer to use for a nested object. In that case, it should use Kryo's read and write methods which accept a serializer.
If the object could be null:
Serializer serializer = ...
kryo.writeObjectOrNull(output, object, serializer);
SomeClass object = kryo.readObjectOrNull(input, SomeClass.class, serializer);
If the object cannot be null:
Serializer serializer = ...
kryo.writeObject(output, object, serializer);
SomeClass object = kryo.readObject(input, SomeClass.class, serializer);
During serialization Kryo getDepth provides the current depth of the object graph.
KryoException
When a serialization fails, a KryoException can be thrown with serialization trace information about where in the object graph the exception occurred. When using nested serializers, KryoException can be caught to add serialization trace information.
Object object = ...
Field[] fields = ...
for (Field field : fields) {
try {
// Use other serializers to serialize each field.
} catch (KryoException ex) {
ex.addTrace(field.getName() + " (" + object.getClass().getName() + ")");
throw ex;
} catch (Throwable t) {
KryoException ex = new KryoException(t);
ex.addTrace(field.getName() + " (" + object.getClass().getName() + ")");
throw ex;
}
}
Stack size
The serializers Kryo provides use the call stack when serializing nested objects. Kryo minimizes stack calls, but a stack overflow can occur for extremely deep object graphs. This is a common issue for most serialization libraries, including the built-in Java serialization. The stack size can be increased using -Xss, but note that this applies to all threads. Large stack sizes in a JVM with many threads may use a large amount of memory.
Kryo setMaxDepth can be used to limit the maximum depth of an object graph. This can prevent malicious data from causing a stack overflow.
Accepting null
By default, serializers will never receive a null, instead Kryo will write a byte as needed to denote null or not null. If a serializer can be more efficient by handling nulls itself, it can call Serializer setAcceptsNull(true). This can also be used to avoid writing the null denoting byte when it is known that all instances the serializer will handle will never be null.
Generics
Kryo getGenerics provides generic type information so serializers can be more efficient. This is most commonly used to avoid writing the class when the type parameter class is final.
Generic type inference is enabled by default and can be disabled with Kryo setOptimizedGenerics(false). Disabling generics optimization can increase performance at the cost of a larger serialized size.
If the class has a single type parameter, nextGenericClass returns the type parameter class, or null if none. After reading or writing any nested objects, popGenericType must be called. See CollectionSerializer for an example.
public class SomeClass<T> {
public T value;
}
public class SomeClassSerializer extends Serializer<SomeClass> {
public void write (Kryo kryo, Output output, SomeClass object) {
Class valueClass = kryo.getGenerics().nextGenericClass();
if (valueClass != null && kryo.isFinal(valueClass)) {
Serializer serializer = kryo.getSerializer(valueClass);
kryo.writeObjectOrNull(output, object.value, serializer);
} else
kryo.writeClassAndObject(output, object.value);
kryo.getGenerics().popGenericType();
}
public SomeClass read (Kryo kryo, Input input, Class<? extends SomeClass> type) {
Class valueClass = kryo.getGenerics().nextGenericClass();
SomeClass object = new SomeClass();
kryo.reference(object);
if (valueClass != null && kryo.isFinal(valueClass)) {
Serializer serializer = kryo.getSerializer(valueClass);
object.value = kryo.readObjectOrNull(input, valueClass, serializer);
} else
object.value = kryo.readClassAndObject(input);
kryo.getGenerics().popGenericType();
return object;
}
}
For a class with multiple type parameters, nextGenericTypes returns an array of GenericType instances and resolve is used to obtain the class for each GenericType. After reading or writing any nested objects, popGenericType must be called. See MapSerializer for an example.
public class SomeClass<K, V> {
public K key;
public V value;
}
public class SomeClassSerializer extends Serializer<SomeClass> {
public void write (Kryo kryo, Output output, SomeClass object) {
Class keyClass = null, valueClass = null;
GenericType[] genericTypes = kryo.getGenerics().nextGenericTypes();
if (genericTypes != null) {
keyClass = genericTypes[0].resolve(kryo.getGenerics());
valueClass = genericTypes[1].resolve(kryo.getGenerics());
}
if (keyClass != null && kryo.isFinal(keyClass)) {
Serializer serializer = kryo.getSerializer(keyClass);
kryo.writeObjectOrNull(output, object.key, serializer);
} else
kryo.writeClassAndObject(output, object.key);
if (valueClass != null && kryo.isFinal(valueClass)) {
Serializer serializer = kryo.getSerializer(valueClass);
kryo.writeObjectOrNull(output, object.value, serializer);
} else
kryo.writeClassAndObject(output, object.value);
kryo.getGenerics().popGenericType();
}
public SomeClass read (Kryo kryo, Input input, Class<? extends SomeClass> type) {
Class keyClass = null, valueClass = null;
GenericType[] genericTypes = kryo.getGenerics().nextGenericTypes();
if (genericTypes != null) {
keyClass = genericTypes[0].resolve(kryo.getGenerics());
valueClass = genericTypes[1].resolve(kryo.getGenerics());
}
SomeClass object = new SomeClass();
kryo.reference(object);
if (keyClass != null && kryo.isFinal(keyClass)) {
Serializer serializer = kryo.getSerializer(keyClass);
object.key = kryo.readObjectOrNull(input, keyClass, serializer);
} else
object.key = kryo.readClassAndObject(input);
if (valueClass != null && kryo.isFinal(valueClass)) {
Serializer serializer = kryo.getSerializer(valueClass);
object.value = kryo.readObjectOrNull(input, valueClass, serializer);
} else
object.value = kryo.readClassAndObject(input);
kryo.getGenerics().popGenericType();
return object;
}
}
For serializers which pass type parameter information for nested objects in the object graph (somewhat advanced usage), first GenericsHierarchy is used to store the type parameters for a class. During serialization, Generics pushTypeVariables is called before generic types are resolved (if any). If >0 is returned, this must be followed by Generics popTypeVariables. See FieldSerializer for an example.
public class SomeClass<T> {
T value;
List<T> list;
}
public class SomeClassSerializer extends Serializer<SomeClass> {
private final GenericsHierarchy genericsHierarchy;
public SomeClassSerializer () {
genericsHierarchy = new GenericsHierarchy(SomeClass.class);
}
public void write (Kryo kryo, Output output, SomeClass object) {
Class valueClass = null;
Generics generics = kryo.getGenerics();
int pop = 0;
GenericType[] genericTypes = generics.nextGenericTypes();
if (genericTypes != null) {
pop = generics.pushTypeVariables(genericsHierarchy, genericTypes);
valueClass = genericTypes[0].resolve(generics);
}
if (valueClass != null && kryo.isFinal(valueClass)) {
Serializer serializer = kryo.getSerializer(valueClass);
kryo.writeObjectOrNull(output, object.value, serializer);
} else
kryo.writeClassAndObject(output, object.value);
kryo.writeClassAndObject(output, object.list);
if (pop > 0) generics.popTypeVariables(pop);
generics.popGenericType();
}
public SomeClass read (Kryo kryo, Input input, Class<? extends SomeClass> type) {
Class valueClass = null;
Generics generics = kryo.getGenerics();
int pop = 0;
GenericType[] genericTypes = generics.nextGenericTypes();
if (genericTypes != null) {
pop = generics.pushTypeVariables(genericsHierarchy, genericTypes);
valueClass = genericTypes[0].resolve(generics);
}
SomeClass object = new SomeClass();
kryo.reference(object);
if (valueClass != null && kryo.isFinal(valueClass)) {
Serializer serializer = kryo.getSerializer(valueClass);
object.value = kryo.readObjectOrNull(input, valueClass, serializer);
} else
object.value = kryo.readClassAndObject(input);
object.list = (List)kryo.readClassAndObject(input);
if (pop > 0) generics.popTypeVariables(pop);
generics.popGenericType();
return object;
}
}
KryoSerializable
Instead of using a serializer, a class can choose to do its own serialization by implementing KryoSerializable (similar to java.io.Externalizable).
public class SomeClass implements KryoSerializable {
private int value;
public void write (Kryo kryo, Output output) {
output.writeInt(value, false);
}
public void read (Kryo kryo, Input input) {
value = input.readInt(false);
}
}
Obviously the instance must already be created before read can be called, so the class isn't able to control its own creation. A KryoSerializable class will use the default serializer KryoSerializableSerializer, which uses Kryo newInstance to create a new instance. It is trivial to write your own serializer to customize the process, call methods before or after serialiation, etc.
Serializer copying
Serializers only support copying if copy is overridden. Similar to Serializer read, this method contains the logic to create and configure the copy. Just like read, Kryo reference must be called before Kryo is used to copy child objects, if any of the child objects could reference the parent object.
class SomeClassSerializer extends Serializer<SomeClass> {
public SomeClass copy (Kryo kryo, SomeClass original) {
SomeClass copy = new SomeClass();
kryo.reference(copy);
copy.intValue = original.intValue;
copy.object = kryo.copy(original.object);
return copy;
}
}
KryoCopyable
Instead of using a serializer, classes can implement KryoCopyable to do their own copying:
public class SomeClass implements KryoCopyable<SomeClass> {
public SomeClass copy (Kryo kryo) {
SomeClass copy = new SomeClass();
kryo.reference(copy);
copy.intValue = intValue;
copy.object = kryo.copy(object);
return copy;
}
}
Immutable serializers
Serializer setImmutable(true) can be used when the type is immutable. In that case, Serializer copy does not need to be implemented -- the default copy implementation will return the original object.
Kryo versioning and upgrading
The following rules of thumb are applied to Kryo's version numbering:
- The major version is increased if serialization compatibility is broken. This means data serialized with a previous version may not be deserialized with the new version.
- The minor version is increased if binary or source compatibility of the documented public API is broken. To avoid increasing the version when very few users are affected, some minor breakage is allowed if it occurs in public classes that are seldom used or not intended for general usage.
Upgrading any dependency is a significant event, but a serialization library is more prone to breakage than most dependencies. When upgrading Kryo check the version differences and test the new version thoroughly in your own applications. We try to make it as safe and easy as possible.
- At development time serialization compatibility is tested for the different binary formats and default serializers.
- At development time binary and source compatibility is tracked with clirr.
- For each release a changelog is provided that also contains a section reporting the serialization, binary, and source compatibilities.
- For reporting binary and source compatibility japi-compliance-checker is used.
Interoperability
The Kryo serializers provided by default assume that Java will be used for deserialization, so they do not explicitly define the format that is written. Serializers could be written using a standardized format that is more easily read by other languages, but this is not provided by default.
Compatibility
For some needs, such as long term storage of serialized bytes, it can be important how serialization handles changes to classes. This is known as forward compatibility (reading bytes serialized by newer classes) and backward compatibility (reading bytes serialized by older classes). Kryo provides a few generic serializers which take different approaches to handling compatibility. Additional serializers can easily be developed for forward and backward compatibility, such as a serializer that uses an external, hand written schema.
Serializers
Kryo provides many serializers with various configuration options and levels of compatibility. Additional serializers can be found in the kryo-serializers sister project, which hosts serializers that access private APIs or are otherwise not perfectly safe on all JVMs. More serializers can be found in the links section.
FieldSerializer
FieldSerializer works by serializing each non-transient field. It can serialize POJOs and many other classes without any configuration. All non-public fields are written and read by default, so it is important to evaluate each class that will be serialized. If fields are public, serialization may be faster.
FieldSerializer is efficient by writing only the field data, without any schema information, using the Java class files as the schema. It does not support adding, removing, or changing the type of fields without invalidating previously serialized bytes. Renaming fields is allowed only if it doesn't change the alphabetical order of the fields.
FieldSerializer's compatibility drawbacks can be acceptable in many situations, such as when sending data over a network, but may not be a good choice for long term data storage because the Java classes cannot evolve.
FieldSerializer settings
| Setting | Description | Default value |
|---|---|---|
fieldsCanBeNull |
When false it is assumed that no field values are null, which can save 0-1 byte per field. | true |
setFieldsAsAccessible |
When true, all non-transient fields (inlcuding private fields) will be serialized and setAccessible if necessary. If false, only fields in the public API will be serialized. |
true |
ignoreSyntheticFields |
If true, synthetic fields (generated by the compiler for scoping) are serialized. | false |
fixedFieldTypes |
If true, it is assumed every field value's concrete type matches the field's type. This removes the need to write the class ID for field values. | false |
copyTransient |
If true, all transient fields will be copied. | true |
serializeTransient |
If true, transient fields will be serialized. | false |
variableLengthEncoding |
If true, variable length values are used for int and long fields. | true |
extendedFieldNames |
If true, field names are prefixed by their declaring class. This can avoid conflicts when a subclass has a field with the same name as a super class. | false |
CachedField settings
FieldSerializer provides the fields that will be serialized. Fields can be removed, so they won't be serialized. Fields can be configured to make serialiation more efficient.
FieldSerializer fieldSerializer = ...
fieldSerializer.removeField("id"); // Won't be serialized.
CachedField nameField = fieldSerializer.getField("name");
nameField.setCanBeNull(false);
CachedField someClassField = fieldSerializer.getField("someClass");
someClassField.setClass(SomeClass.class, new SomeClassSerializer());
| Setting | Description | Default value |
|---|---|---|
canBeNull |
When false it is assumed the field value is never null, which can save 0-1 byte. | true |
valueClass |
Sets the concrete class and serializer to use for the field value. This removes the need to write the class ID for the value. If the field value's class is a primitive, primitive wrapper, or final, this setting defaults to the field's class. | null |
serializer |
Sets the serializer to use for the field value. If the serializer is set, some serializers required the value class to also be set. If null, the serializer registered with Kryo for the field value's class will be used. | null |
variableLengthEncoding |
If true, variable length values are used. This only applies to int or long fields. | true |
optimizePositive |
If true, positive values are optimized for variable length values. This only applies to int or long fields when variable length encoding is used. | true |
FieldSerializer annotations
Annotations can be used to configure the serializers for each field.
| Annotation | Description |
|---|---|
@Bind |
Sets the CachedField settings for any field. |
@CollectionBind |
Sets the CollectionSerializer settings for Collection fields. |
@MapBind |
Sets the MapSerializer settings for Map fields. |
@NotNull |
Marks a field as never being null. |
public class SomeClass {
@NotNull
@Bind(serializer = StringSerializer.class, valueClass = String.class, canBeNull = false)
Object stringField;
@Bind(variableLengthEncoding = false)
int intField;
@BindMap(
keySerializer = StringSerializer.class,
valueSerializer = IntArraySerializer.class,
keyClass = String.class,
valueClass = int[].class,
keysCanBeNull = false)
Map map;
@BindCollection(
elementSerializer = LongArraySerializer.class,
elementClass = long[].class,
elementsCanBeNull = false)
Collection collection;
}
VersionFieldSerializer
VersionFieldSerializer extends FieldSerializer and provides backward compatibility. This means fields can be added without invalidating previously serialized bytes. Removing, renaming, or changing the type of a field is not supported.
When a field is added, it must have the @Since(int) annotation to indicate the version it was added in order to be compatible with previously serialized bytes. The annotation value must never change.
VersionFieldSerializer adds very little overhead to FieldSerializer: a single additional varint.
VersionFieldSerializer settings
| Setting | Description | Default value |
|---|---|---|
compatible |
When false, an exception is thrown when reading an object with a different version. The version of an object is the maximum version of any field. | true |
VersionFieldSerializer also inherits all the settings of FieldSerializer.
TaggedFieldSerializer
TaggedFieldSerializer extends FieldSerializer to provide backward compatibility and optional forward compatibility. This means fields can be added or renamed and optionally removed without invalidating previously serialized bytes. Changing the type of a field is not supported.
Only fields that have a @Tag(int) annotation are serialized. Field tag values must be unique, both within a class and all its super classes. An exception is thrown if duplicate tag values are encountered.
The forward and backward compatibility and serialization performance depends on the readUnknownTagData and chunkedEncoding settings. Additionally, a varint is written before each field for the tag value.
When readUnknownTagData and chunkedEncoding are false, fields must not be removed but the @Deprecated annotation can be applied. Deprecated fields are read when reading old bytes but aren't written to new bytes. Classes can evolve by reading the values of deprecated fields and writing them elsewhere. Fields can be renamed and/or made private to reduce clutter in the class (eg, ignored1, ignored2).
TaggedFieldSerializer settings
| Setting | Description | Default value |
|---|---|---|
readUnknownTagData |
When false and an unknown tag is encountered, an exception is thrown or, if chunkedEncoding is true, the data is skipped.When true, the class for each field value is written before the value. When an unknown tag is encountered, an attempt to read the data is made. This is used to skip the data and, if references are enabled, any other values in the object graph referencing that data can still be deserialized. If reading the data fails (eg the class is unknown or has been removed) then an exception is thrown or, if chunkedEncoding is true, the data is skipped.In either case, if the data is skipped and references are enabled, then any references in the skipped data are not read and further deserialization may receive the wrong references and fail. |
|
chunkedEncoding |
When true, fields are written with chunked encoding to allow unknown field data to be skipped. This impacts performance. | false |
chunkSize |
The maximum size of each chunk for chunked encoding. | 1024 |
TaggedFieldSerializer also inherits all the settings of FieldSerializer.
CompatibleFieldSerializer
CompatibleFieldSerializer extends FieldSerializer to provided both forward and backward compatibility. This means fields can be added or removed without invalidating previously serialized bytes. Renaming or changing the type of a field is not supported. Like FieldSerializer, it can serialize most classes without needing annotations.
The forward and backward compatibility and serialization performance depends on the readUnknownFieldData and chunkedEncoding settings. Additionally, the first time the class is encountered in the serialized bytes, a simple schema is written containing the field name strings. Because field data is identified by name, if a super class has a field with the same name as a subclass, extendedFieldNames must be true.
CompatibleFieldSerializer settings
| Setting | Description | Default value |
|---|---|---|
readUnknownFieldData |
When false and an unknown field is encountered, an exception is thrown or, if chunkedEncoding is true, the data is skipped.When true, the class for each field value is written before the value. When an unknown field is encountered, an attempt to read the data is made. This is used to skip the data and, if references are enabled, any other values in the object graph referencing that data can still be deserialized. If reading the data fails (eg the class is unknown or has been removed) then an exception is thrown or, if chunkedEncoding is true, the data is skipped.In either case, if the data is skipped and references are enabled, then any references in the skipped data are not read and further deserialization may receive the wrong references and fail. |
|
chunkedEncoding |
When true, fields are written with chunked encoding to allow unknown field data to be skipped. This impacts performance. | false |
chunkSize |
The maximum size of each chunk for chunked encoding. | 1024 |
CompatibleFieldSerializer also inherits all the settings of FieldSerializer.
BeanSerializer
BeanSerializer is very similar to FieldSerializer, except it uses bean getter and setter methods rather than direct field access. This slightly slower, but may be safer because it uses the public API to configure the object. Like FieldSerializer, it provides no forward or backward compatibility.
CollectionSerializer
CollectionSerializer serializes objects that implement the java.util.Collection interface.
CollectionSerializer settings
| Setting | Description | Default value |
|---|---|---|
elementsCanBeNull |
When false it is assumed that no elements in the collection are null, which can save 0-1 byte per element. | true |
elementClass |
Sets the concrete class to use for each element in the collection. This removes the need to write the class ID for each element. If the element class is known (eg through generics) and a primitive, primitive wrapper, or final, then CollectionSerializer won't write the class ID even when this setting is null. | null |
elementSerializer |
Sets the serializer to use for every element in the collection. If the serializer is set, some serializers required the value class to also be set. If null, the serializer registered with Kryo for each element's class will be used. | null |
MapSerializer
MapSerializer serializes objects that implement the java.util.Map interface.
MapSerializer settings
| Setting | Description | Default value |
|---|---|---|
keysCanBeNull |
When false it is assumed that no keys in the map are null, which can save 0-1 byte per entry. | true |
valuesCanBeNull |
When false it is assumed that no values in the map are null, which can save 0-1 byte per entry. | true |
keyClass |
Sets the concrete class to use for every key in the map. This removes the need to write the class ID for each key. | null |
valueClass |
Sets the concrete class to use for every value in the map. This removes the need to write the class ID for each value. | null |
keySerializer |
Sets the serializer to use for every key in the map. If the value serializer is set, some serializers required the value class to also be set. If null, the serializer registered with Kryo for each key's class will be used. | null |
valueSerializer |
Sets the serializer to use for every value in the map. If the key serializer is set, some serializers required the value class to also be set. If null, the serializer registered with Kryo for each value's class will be used. | null |
JavaSerializer and ExternalizableSerializer
JavaSerializer and ExternalizableSerializer are Kryo serializers which uses Java's built-in serialization. This is as slow as usual Java serialization, but may be necessary for legacy classes.
java.io.Externalizable and java.io.Serializable do not have default serializers set by default, so the default serializers must be set manually or the serializers set when the class is registered.
class SomeClass implements Externalizable { /* ... */ }
kryo.addDefaultSerializer(Externalizable.class, ExternalizableSerializer.class);
kryo.register(SomeClass.class);
kryo.register(SomeClass.class, new JavaSerializer());
kryo.register(SomeClass.class, new ExternalizableSerializer());
Logging
Kryo makes use of the low overhead, lightweight MinLog logging library. The logging level can be set by one of the following methods:
Log.ERROR();
Log.WARN();
Log.INFO();
Log.DEBUG();
Log.TRACE();
Kryo does no logging at INFO (the default) and above levels. DEBUG is convenient to use during development. TRACE is good to use when debugging a specific problem, but generally outputs too much information to leave on.
MinLog supports a fixed logging level, which causes the Java compiler to remove logging statements below that level at compile time. Kryo must be compiled with a fixed logging level MinLog JAR.
Thread safety
Kryo is not thread safe. Each thread should have its own Kryo, Input, and Output instances.
Pooling
Because Kryo is not thread safe and constructing and configuring a Kryo instance is relatively expensive, in a multithreaded environment ThreadLocal or pooling might be considered.
static private final ThreadLocal<Kryo> kryos = new ThreadLocal<Kryo>() {
protected Kryo initialValue() {
Kryo kryo = new Kryo();
// Configure the Kryo instance.
return kryo;
};
};
Kryo kryo = kryos.get();
For pooling, Kryo provides the Pool class which can pool Kryo, Input, Output, or instances of any other class.
// Pool constructor arguments: thread safe, soft references, maximum capacity
Pool<Kryo> kryoPool = new Pool<Kryo>(true, false, 8) {
protected Kryo create () {
Kryo kryo = new Kryo();
// Configure the Kryo instance.
return kryo;
}
};
Kryo kryo = kryoPool.obtain();
// Use the Kryo instance here.
kryoPool.free(kryo);
Pool<Output> outputPool = new Pool<Output>(true, false, 16) {
protected Output create () {
return new Output(1024, -1);
}
};
Output output = outputPool.obtain();
// Use the Output instance here.
outputPool.free(output);
Pool<Input> inputPool = new Pool<Input>(true, false, 16) {
protected Input create () {
return new Input(1024, -1);
}
};
Input input = inputPool.obtain();
// Use the Input instance here.
inputPool.free(input);
If true is passed as the first argument to the Pool constructor, the Pool uses synchronization internally and can be accessed by multiple threads concurrently.
If true is passed as the second argument to the Pool constructor, the Pool stores objects using java.lang.ref.SoftReference. This allows objects in the pool to be garbage collected when memory pressure on the JVM is high. Pool clean removes all soft references whose object has been garbage collected. This can reduce the size of the pool when no maximum capacity has been set. When the pool has a maximum capacity, it is not necessary to call clean because Pool free will try to remove an empty reference if the maximum capacity has been reached.
The third Pool parameter is the maximum capacity. If an object is freed and the pool already contains the maximum number of free objects, the specified object is reset but not added to the pool. The maximum capacity may be omitted for no limit.
If an object implements Pool.Poolable then Poolable reset is called when the object is freed. This gives the object a chance to reset its state for reuse in the future. Alternatively, Pool reset can be overridden to reset objects. Input and Output implement Poolable to set their position and total to 0. Kryo does not implement Poolable because its object graph state is typically reset automatically after each serialization (see Reset). If you disable automatic reset via setAutoReset(false), make sure that you call Kryo.reset() before returning the instance to the pool.
Pool getFree returns the number of objects available to be obtained. If using soft references, this number may include objects that have been garbage collected. clean may be used first to remove empty soft references.
Pool getPeak returns the all-time highest number of free objects. This can help determine if a pool's maximum capacity is set appropriately. It can be reset any time with resetPeak.
Benchmarks
Kryo provides a number of JMH-based benchmarks and R/ggplot2 files.
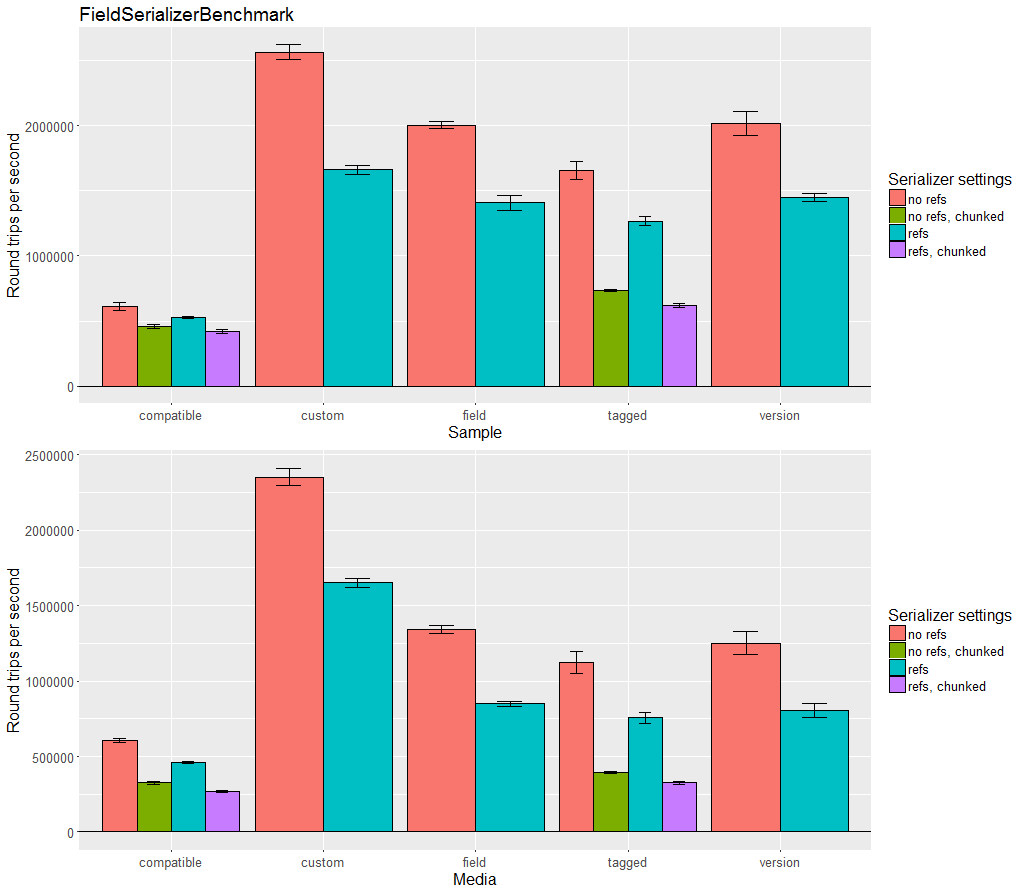
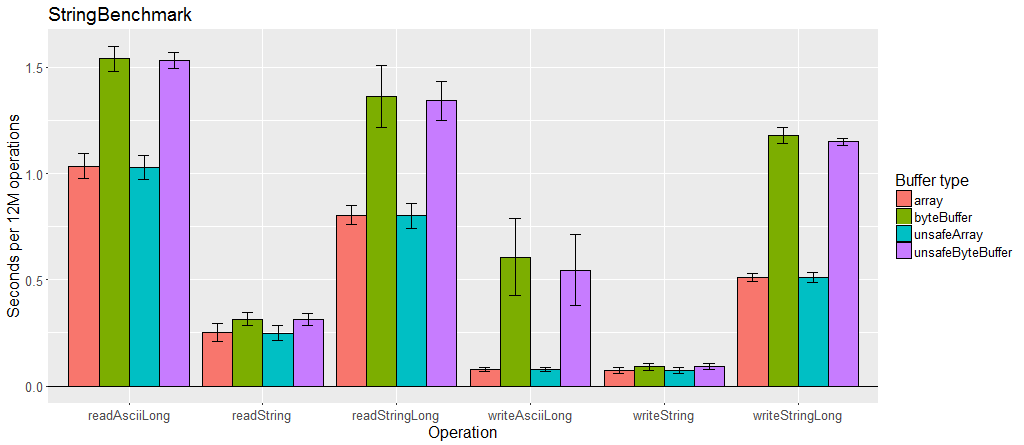
Kryo can be compared to many other serialization libraries in the JVM Serializers project. The benchmarks are small, dated, and homegrown rather than using JMH, so are less trustworthy. Also, it is very difficult to thoroughly compare serialization libraries using a benchmark. Libraries have many different features and often have different goals, so they may excel at solving completely different problems. To understand these benchmarks, the code being run and data being serialized should be analyzed and contrasted with your specific needs. Some serializers are highly optimized and use pages of code, others use only a few lines. This is good to show what is possible, but may not be a relevant comparison for many situations.
Links
Projects using Kryo
There are a number of projects using Kryo. A few are listed below. Please submit a pull request if you'd like your project included here.
- KryoNet (NIO networking)
- kryo-serializers (additional serializers)
- Twitter's Scalding (Scala API for Cascading)
- Twitter's Chill (Kryo serializers for Scala)
- Apache Fluo (Kryo is default serialization for Fluo Recipes)
- Apache Hive (query plan serialization)
- Apache Spark (shuffled/cached data serialization)
- DataNucleus (JDO/JPA persistence framework)
- CloudPelican
- Yahoo's S4 (distributed stream computing)
- Storm (distributed realtime computation system, in turn used by many others)
- Cascalog (Clojure/Java data processing and querying details)
- memcached-session-manager (Tomcat high-availability sessions)
- Mobility-RPC (RPC enabling distributed applications)
- akka-kryo-serialization (Kryo serializers for Akka)
- Groupon
- Jive
- DestroyAllHumans (controls a robot!)
- Mybatis Redis-Cache (MyBatis Redis Cache adapter)
- Apache Dubbo (high performance, open source RPC framework)
Scala
- Twitter's Chill (Kryo serializers for Scala)
- akka-kryo-serialization (Kryo serializers for Scala and Akka)
- Twitter's Scalding (Scala API for Cascading)
- Kryo Serializers (Additional serializers for Java)
- Kryo Macros (Scala macros for compile-time generation of Kryo serializers)
Clojure
- Carbonite (Kryo serializers for Clojure)
Objective-C
- kryococoa (Objective-C port of Kryo)
